Daniel Jacobson, Director of Engineering – Netflix API, uses some terms in his post, The future of API design: The orchestration layer, that are making things difficult for those of us trying to communicate in the API space. Specifically, the two terms, “API Orchestration Layer” and “Experience API.” These are neither accurate nor meaningful. Let me explain…
API Orchestration Layer
From Daniel’s post:
An API Orchestration Layer (OL) is an abstraction layer that takes generically-modeled data elements and/or features and prepares them in a more specific way for a targeted developer or application
This concept is describing an Aggregation Layer, not an orchestration layer. Per the almighty, always-true, Wikipedia:
Orchestration describes the automated arrangement, coordination, and management of complex computer systems, middleware, and services.
An orchestration layer determines order and sequence, orchestrating events and sequencing of messages in a service-oriented architecture. On the other hand, an aggregation layer performs operations and data transformation to provide a specific payload for a specific client. Both are useful, but don’t confuse the two.
Let’s talk about aggregation where we mean aggregation and orchestration where we mean orchestration.
Experience APIs
There is no such distinction. Nor should there be. Let me be clear: Every API is an experience API!
Make no mistake, no matter whether you’re targeting internal develops, third-party integrators or public developers, those folks have an experience with your API (good or otherwise). However, now I’m hearing businesses talking about how they don’t need to design their RESTful APIs, since they’re just going to put an “experience API” on top of it. Please stop using the term.
Appropriate alternatives are: Public API, Internal API, Crappy API, REST API, etc.
In Short
APIs are the new and shiny thing that businesses are currently chasing for the sake of being part of the so-called “API economy.” Understanding is important. APIs are confusing enough without using a ubiquitous language to describe what we mean. Can we agree to use accurate terms?
Here’s a quickie video describing the application layers of a RestExpress application when one of the Maven Archetypes is used to create a new RestExpress project.
To summarize: Visibility or “awareness” goes down. Meaning that a layer can call (or know about) the layer immediately below it, but an application layer cannot call the layer above it or a layer deeper than the next immediately lower. In other words, if there’s database orchestration code in the Service Layer or Controller, that’s poor design. And conversely, if there’s HTTP header, request or response manipulation in the ServiceLayer or Persistence Layer, that’d be bad.
Layer #1: Controller/HTTP Layer
HTTP layer where requests, headers and responses are manipulated and processed.
Handles serialization of request body to domain model.
And deserialization from domain model to response.
Makes call to only the Service Layer (layer #2).
Layer #2: Service Layer
Business logic.
Calls methods on domain model to orchestrate business logic and domain functionality.
Calls Persistence Layer to store and read domain model instances.
Returns domain model instances to the Controller/ HTTP Layer.
Layer #3: Persistence Layer
Sometimes call DAL (data access layer) or DAO (data accessor object).
Called Repository by Eric Evans in his Domain Driven Design (DDD) book.
Creates an interface to perform queries and database operations.
“Serializes” and “deserializes” domain model instances to/from the database.
The public face of a business system is its user interface (UI)–the part the end-user sees. Businesses often think in terms of user interface design. Many times they also consider it the facet that gives them an edge in their market (the “killer app”). Being overly concerned with the UI first, focusing on what the web interface or mobile application looks like, often means duplicating complicated business logic across those UIs. This makes the user interface very difficult to maintain and morph over time as business needs shift.
The Problem
Mobile-first is a term that’s created a lot of buzz lately. So much so as to render the term largely meaningless. However, it does point to a great need: the need to revise or even provide new user interfaces for business systems as channels change and new ones become available. But with all that complicated business logic captured in Web applications, JavaScript, native IOS and Android applications, it’s very expensive to start over when creating a new user interface.
We need to be able to throw UIs away and start over with minimal cost. Or create new UIs for new channels and/or devices without duplicating all that business logic. The real asset must be the business logic encapsulated in our back-end business systems. These systems should provide the ability to be UI agnostic. In other words, the face of the business system (e.g. user interface) should be able to change drastically over time without compromising business processes and should have minimal cost.
This is not the case today.
Enter the Shiny REST
APIs should encapsulate both processes and data
There’s a shiny new kid on the block called REST APIs. Maybe you’ve heard of them? They promise easy integration, new business partners, reduced time to market, reduced development cost, increased revenue models, more income, improved creativity & innovation, architectural coolness, singing angels, and maybe even the voice of God saying, “Well done!” At least if you listen to the hype.
In most Web applications, such as Java/JSP stacks, the user interface is intrinsically linked to the back-end business logic and right down to the database. And while service-oriented architectures (SOA) encourages loose coupling between components, the focus is on behavior not data. Putting a UI on those processes is difficult.
The promise of REST APIs is largely that business logic and data is encapsulated behind a suite of HTTP resources. However, at the time of this writing, most businesses seem to be looking at REST APIs because they’re new and shiny, much like businesses “needed” a website to be successful in the late nineties.
The promise has yet to be realized!
Business systems are both data and process. The problem with most Web APIs (we can argue whether they’re truly REST-ful later) is that they only expose data to the outside world, excluding business processes altogether. Typically, the sequence of API calls and details about state changes are shared out-of-band in documentation about the API and are not part of the API request/response cycle itself. This inhibits business logic from being part of the API and pushes business logic into any user interface written on that API.
This is not optimal, in case you were wondering.
To realize the dream, an API must encapsulate both processes and data!
An API for Processes?
Modeling processing within a REST/Web API may seem foreign at first. At least until we consider that HTML has supported the concept for years, with links, inputs, and forms. Leveraging these concepts within a REST API (right in a JSON payload), we can take our APIs to the next level, encapsulating both data and business logic.
In essence, by using links and forms in our REST APIs, our APIs become more like state machines. These state machines, with both data and behavior (transitions), can model extremely scalable, maintainable, arbitrarily-complex business processes.
This is the realization of Roy Fielding’s “hypertext as the engine of application state” (HATEOAS) constraint of REST.
So how do we model a data and behavior in an API? In essence, it’s media types that enable us to expose links, actions and forms within our API payloads. Which, in turn, enable us to model complex business processes without moving that business logic to the client.
State-Machine APIs
As mentioned, a typical API response today will only contain data. More advanced ones expose links (say via the HAL media type). Even more advanced representations, capable of modeling state machines, contain more-than just links and data, adding actions and forms. Media types such as the Siren, Collection+JSON, and HALe are good examples.
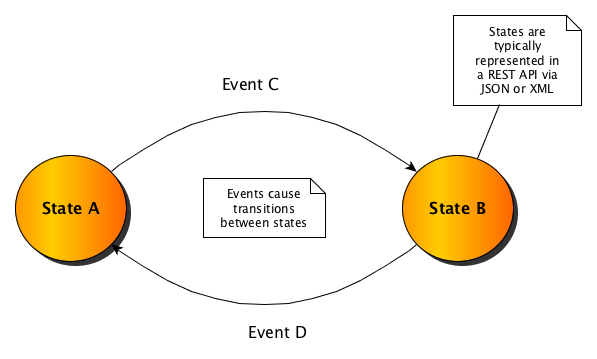
Consider the following simple state-machine diagram.
In it are two states, state A & state B. The state-machine changes from state A to state B when event C occurs (note that the state-machine must be in state A for event C to occur). Additionally, the state machine goes from state B to state A when event D occurs.
A Lighting System Example
If the above state machine is implemented by a REST API with states A & B represented by JSON and the events are generated by actions on that API. Let’s say the API represents a lighting system with off & on states (representing state A and B, respectively), with events of turn-on and turn-off (representing events C and D, respectively).
Initial state A of off might be represented in JSON (using my own invented state-machine media type) as:
Although the above example is extremely simple, it illustrates the key point that a user interface for our lighting system could be created without any business logic since the API contains all the possible actions that the user interface can make.
There’s no URL construction within the UI code base, no if-then-else logic to determine possible actions based on the value of the status property. It only needs to utilize the possible actions in the _actions property.
This is very powerful. APIs of the future will enable the commoditization of the user interface by encapsulating both data and business logic.
What are your thoughts? Enter a comment below about your thoughts and experiences.
Idempotence is sometimes a confusing concept, especially when you try to understand the academic definition. However, understanding what makes a REST API operation idempotent is simple with the concept introduced in this short, somewhat humorous look at Idempotency in Cows & REST APIs…
TIP: Publicly exposed identifiers (IDs), such as those exposed in your RESTful URLs, should not expose underlying technology. And in most cases, should not contain business meaning.
For a long time it’s been good practice to ensure that primary keys in your database tables do not contain business semantics so that it doesn’t change when the business meaning changes. We’ve all seen the cases where either SSN, phone number, or email address utilized as a primary key turns out to be a bad choice.
If you’re familiar with this practice, then it’s not news to you that IDs exposed in REST APIs generally have the same rules–a URL is supposed to uniquely identify a resource and not change over time.
The Problem
The catch is that often we end up exposing our underlying technology in those identifiers. Consider the case where we have a URL like /users/12345, where the 12345 is a user identifier. Is that the underlying database column, perhaps MySQL, where the user_id column is a long or AUTOSEQUENCE? Problemo when you reimplement your user resources in MongoDB and decide to use the MongoDB ObjectID which looks something like 4e20885deabfa3a2586b5fb1.
Even more subtle is when we expose a mixture of some MySQL tables, MongoDB documents, Cassandra keyspaces, or Redis objects and expose their IDs in URLs. Your RESTful APIs can look quite cluttered and be confusing to your consumers.
The Proposal
Nearly all databases, whether NoSQL or relational, now support the concept of a UUID (universally-unique identifier). It is a 16-byte (128-bit) binary representation, when displayed as a string is 32 hexadecimal digits, displayed in five groups separated by hyphens for a total of 36 characters (32 alphanumeric characters plus four hyphens). For example (see the wikipedia link above for more detail):
550e8400-e29b-41d4-a716-446655440000
While those 36 characters are cumbersome to type, using a Type 4 (random) UUID as primary keys, row keys, etc. in databases makes things appear much more cohesive where unique identifiers are exposed in your RESTful APIs. And besides, most of the time the ID is simply used by a JavaScript or other consumer that doesn’t care how long the IDs are in your URL.
One More Thing
Don’t like all those characters and hyphens in your URL? Well, you can Base64 encode your UUIDs before displaying them in URLs and Base64 decode them on the way back in–except that Base64 is not URL safe! So you have to either URL encode/decode them or use a URL-safe Base64 encoder/decoder (like that available in RestExpress’s own RepoExpress UuidConverter). This will get your UUIDs down to 22 characters instead of the normal 36.
Recommendation: IDs generated by an API are in the form of web-safe, base64-encoded UUIDs, which are 22 characters in length. For example, “abcdEFh4520juieUKHWgJQ” instead of “550e8400-e29b-41d4-a716-446655440000.”
Feedback? What are your thoughts and experiences. Please offer your comments below…

 In it are two states, state A & state B. The state-machine changes from state A to state B when event C occurs (note that the state-machine must be in state A for event C to occur). Additionally, the state machine goes from state B to state A when event D occurs.
In it are two states, state A & state B. The state-machine changes from state A to state B when event C occurs (note that the state-machine must be in state A for event C to occur). Additionally, the state machine goes from state B to state A when event D occurs. TIP: Publicly exposed identifiers (IDs), such as those exposed in your RESTful URLs, should not expose underlying technology. And in most cases, should not contain business meaning.
TIP: Publicly exposed identifiers (IDs), such as those exposed in your RESTful URLs, should not expose underlying technology. And in most cases, should not contain business meaning.